
Paper List
-
The Effective Reproduction Number in the Kermack-McKendrick model with age of infection and reinfection
This paper addresses the challenge of accurately estimating the time-varying effective reproduction number ℛ(t) in epidemics by incorporating two crit...
-
Covering Relations in the Poset of Combinatorial Neural Codes
This work addresses the core challenge of navigating the complex poset structure of neural codes to systematically test the conjecture linking convex ...
-
Collective adsorption of pheromones at the water-air interface
This paper addresses the core challenge of understanding how amphiphilic pheromones, previously assumed to be transported in the gas phase, can be sta...
-
pHapCompass: Probabilistic Assembly and Uncertainty Quantification of Polyploid Haplotype Phase
This paper addresses the core challenge of accurately assembling polyploid haplotypes from sequencing data, where read assignment ambiguity and an exp...
-
Setting up for failure: automatic discovery of the neural mechanisms of cognitive errors
This paper addresses the core challenge of automating the discovery of biologically plausible recurrent neural network (RNN) dynamics that can replica...
-
Influence of Object Affordance on Action Language Understanding: Evidence from Dynamic Causal Modeling Analysis
This study addresses the core challenge of moving beyond correlational evidence to establish the *causal direction* and *temporal dynamics* of how obj...
-
Revealing stimulus-dependent dynamics through statistical complexity
This paper addresses the core challenge of detecting stimulus-specific patterns in neural population dynamics that remain hidden to traditional variab...
-
Exactly Solvable Population Model with Square-Root Growth Noise and Cell-Size Regulation
This paper addresses the fundamental gap in understanding how microscopic growth fluctuations, specifically those with size-dependent (square-root) no...
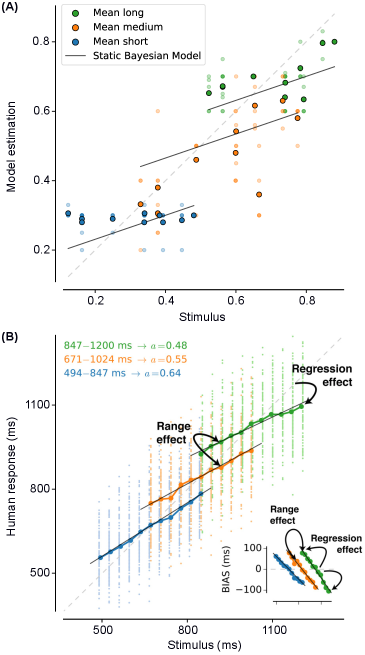
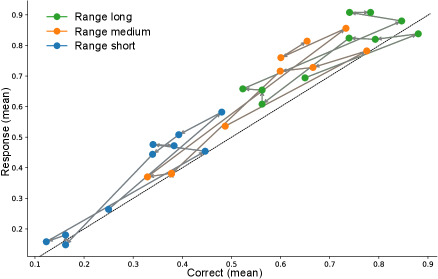
Emergent Bayesian Behaviour and Optimal Cue Combination in LLMs
Huawei Noah’s Ark Lab, London, UK | AI Centre, Department of Computer Science, University College London, London, UK
30秒速读
IN SHORT: This paper addresses the critical gap in understanding whether LLMs spontaneously develop human-like Bayesian strategies for processing uncertain information, revealing that high accuracy does not guarantee robust multimodal integration.
核心创新
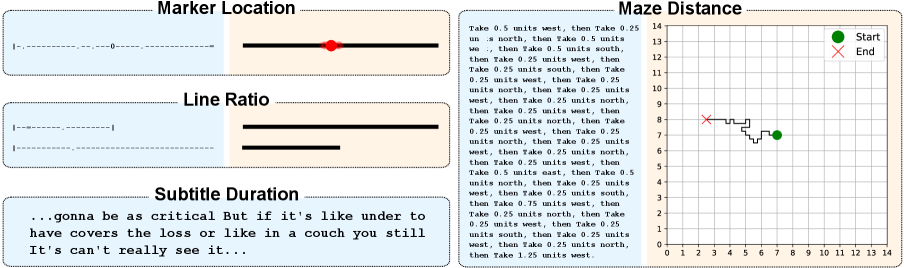
- Methodology Introduces BayesBench, the first psychophysics-inspired behavioral benchmark for LLMs with four magnitude estimation tasks (length, location, distance, duration) across text and image modalities.
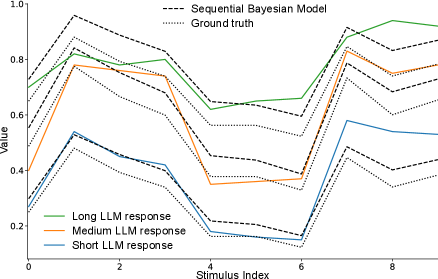
- Methodology Develops Bayesian Consistency Score (BCS) to detect Bayes-consistent behavioral shifts even when accuracy saturates, enabling separation of capability from computational strategy.
- Biology Demonstrates emergent Bayesian behavior in capable LLMs without explicit training, with Llama-4 Maverick showing cue-combination efficiency exceeding human biological systems (RRE > 1 against Bayesian oracle).
主要结论
- GPT-5 Mini achieves perfect text accuracy (NRMSE ≈ 0) but fails to integrate visual cues efficiently, showing poor cue-combination efficiency (RRE < 1) despite high capability.
- Llama-4 Maverick demonstrates emergent Bayesian behavior with cue-combination efficiency exceeding Bayesian reliability-weighted baselines (RRE > 1), suggesting non-linear integration strategies.
- Bayesian Consistency Score reveals that more accurate models show stronger evidence of Bayesian behavior, with BCS positively correlated with accuracy across nine evaluated LLMs.
摘要: Large language models (LLMs) excel at explicit reasoning, but their implicit computational strategies remain underexplored. Decades of psychophysics research show that humans intuitively process and integrate noisy signals using near-optimal Bayesian strategies in perceptual tasks. We ask whether LLMs exhibit similar behaviour and perform optimal multimodal integration without explicit training or instruction. Adopting the psychophysics paradigm, we infer computational principles of LLMs from systematic behavioural studies. We introduce a behavioural benchmark - BayesBench: four magnitude estimation tasks (length, location, distance, and duration) over text and image, inspired by classic psychophysics, and evaluate a diverse set of nine LLMs alongside human judgments for calibration. Through controlled ablations of noise, context, and instruction prompts, we measure performance, behaviour and efficiency in multimodal cue-combination. Beyond accuracy and efficiency metrics, we introduce a Bayesian Consistency Score that detects Bayes-consistent behavioural shifts even when accuracy saturates. Our results show that while capable models often adapt in Bayes-consistent ways, accuracy does not guarantee robustness. Notably, GPT-5 Mini achieves perfect text accuracy but fails to integrate visual cues efficiently. This reveals a critical dissociation between capability and strategy, suggesting accuracy-centric benchmarks may over-index on performance while missing brittle uncertainty handling. These findings reveal emergent principled handling of uncertainty and highlight the correlation between accuracy and Bayesian tendencies. We release our psychophysics benchmark and consistency metric as evaluation tools and to inform future multimodal architecture designs111Project webpage: https://bayes-bench.github.io.