
Paper List
-
The Effective Reproduction Number in the Kermack-McKendrick model with age of infection and reinfection
This paper addresses the challenge of accurately estimating the time-varying effective reproduction number ℛ(t) in epidemics by incorporating two crit...
-
Covering Relations in the Poset of Combinatorial Neural Codes
This work addresses the core challenge of navigating the complex poset structure of neural codes to systematically test the conjecture linking convex ...
-
Collective adsorption of pheromones at the water-air interface
This paper addresses the core challenge of understanding how amphiphilic pheromones, previously assumed to be transported in the gas phase, can be sta...
-
pHapCompass: Probabilistic Assembly and Uncertainty Quantification of Polyploid Haplotype Phase
This paper addresses the core challenge of accurately assembling polyploid haplotypes from sequencing data, where read assignment ambiguity and an exp...
-
Setting up for failure: automatic discovery of the neural mechanisms of cognitive errors
This paper addresses the core challenge of automating the discovery of biologically plausible recurrent neural network (RNN) dynamics that can replica...
-
Influence of Object Affordance on Action Language Understanding: Evidence from Dynamic Causal Modeling Analysis
This study addresses the core challenge of moving beyond correlational evidence to establish the *causal direction* and *temporal dynamics* of how obj...
-
Revealing stimulus-dependent dynamics through statistical complexity
This paper addresses the core challenge of detecting stimulus-specific patterns in neural population dynamics that remain hidden to traditional variab...
-
Exactly Solvable Population Model with Square-Root Growth Noise and Cell-Size Regulation
This paper addresses the fundamental gap in understanding how microscopic growth fluctuations, specifically those with size-dependent (square-root) no...
Few-shot Protein Fitness Prediction via In-context Learning and Test-time Training
Department of Systems Biology, Harvard Medical School | Department of Biology, University of Copenhagen | Machine Intelligence, Novo Nordisk A/S | Microsoft Research, Cambridge, MA, USA | Dept. of Applied Mathematics and Computer Science, Technical University of Denmark
30秒速读
IN SHORT: This paper addresses the core challenge of accurately predicting protein fitness with only a handful of experimental observations, where data collection is prohibitively expensive and label availability is severely limited.
核心创新
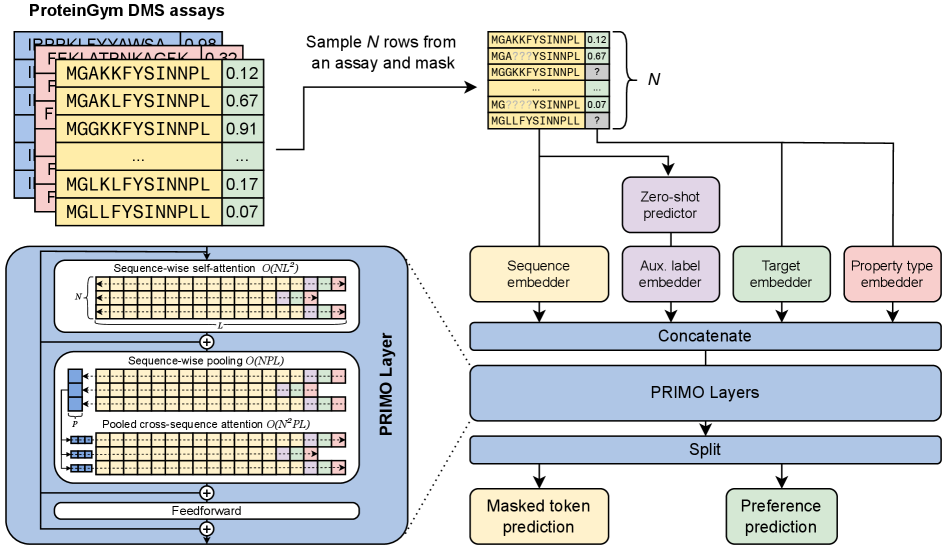
- Methodology Introduces PRIMO, a novel transformer-based framework that uniquely combines in-context learning with test-time training for few-shot protein fitness prediction.
- Methodology Proposes a hybrid masked token reconstruction objective with a preference-based loss function, enabling effective learning from sparse experimental labels across diverse assays.
- Methodology Develops a lightweight pooling attention mechanism that handles both substitution and indel mutations while maintaining computational efficiency, overcoming limitations of previous methods.
主要结论
- PRIMO with test-time training (TTT) achieves state-of-the-art few-shot performance, improving from a zero-shot Spearman correlation of 0.51 to 0.67 with 128 shots, outperforming Gaussian Process (0.56) and Ridge Regression (0.63) baselines.
- The framework demonstrates broad applicability across protein properties including stability (0.77 correlation with TTT), enzymatic activity (0.61), fluorescence (0.30), and binding (0.69), handling both substitution and indel mutations.
- PRIMO's performance highlights the critical importance of proper data splitting to avoid inflated results, as demonstrated by the 0.4 correlation inflation on RL40A_YEAST when using Metalic's overlapping train-test split.
摘要: Accurately predicting protein fitness with minimal experimental data is a persistent challenge in protein engineering. We introduce PRIMO (PRotein In-context Mutation Oracle), a transformer-based framework that leverages in-context learning and test-time training to adapt rapidly to new proteins and assays without large task-specific datasets. By encoding sequence information, auxiliary zero-shot predictions, and sparse experimental labels from many assays as a unified token set in a pre-training masked-language modeling paradigm, PRIMO learns to prioritize promising variants through a preference-based loss function. Across diverse protein families and properties—including both substitution and indel mutations—PRIMO outperforms zero-shot and fully supervised baselines. This work underscores the power of combining large-scale pre-training with efficient test-time adaptation to tackle challenging protein design tasks where data collection is expensive and label availability is limited.