
Paper List
-
Evolutionarily Stable Stackelberg Equilibrium
通过要求追随者策略对突变入侵具有鲁棒性,弥合了斯塔克尔伯格领导力模型与演化稳定性之间的鸿沟。
-
Recovering Sparse Neural Connectivity from Partial Measurements: A Covariance-Based Approach with Granger-Causality Refinement
通过跨多个实验会话累积协方差统计,实现从部分记录到完整神经连接性的重建。
-
Atomic Trajectory Modeling with State Space Models for Biomolecular Dynamics
ATMOS通过提供一个基于SSM的高效框架,用于生物分子的原子级轨迹生成,弥合了计算昂贵的MD模拟与时间受限的深度生成模型之间的差距。
-
Slow evolution towards generalism in a model of variable dietary range
通过证明是种群统计噪声(而非确定性动力学)驱动了模式形成和泛化食性的演化,解决了间接竞争下物种形成的悖论。
-
Grounded Multimodal Retrieval-Augmented Drafting of Radiology Impressions Using Case-Based Similarity Search
通过将印象草稿基于检索到的历史病例,并采用明确引用和基于置信度的拒绝机制,解决放射学报告生成中的幻觉问题。
-
Unified Policy–Value Decomposition for Rapid Adaptation
通过双线性分解在策略和价值函数之间共享低维目标嵌入,实现对新颖任务的零样本适应。
-
Mathematical Modeling of Cancer–Bacterial Therapy: Analysis and Numerical Simulation via Physics-Informed Neural Networks
提供了一个严格的、无网格的PINN框架,用于模拟和分析细菌癌症疗法中复杂的、空间异质的相互作用。
-
Sample-Efficient Adaptation of Drug-Response Models to Patient Tumors under Strong Biological Domain Shift
通过从无标记分子谱中学习可迁移表征,利用最少的临床数据实现患者药物反应的有效预测。
Few-shot Protein Fitness Prediction via In-context Learning and Test-time Training
Department of Systems Biology, Harvard Medical School | Department of Biology, University of Copenhagen | Machine Intelligence, Novo Nordisk A/S | Microsoft Research, Cambridge, MA, USA | Dept. of Applied Mathematics and Computer Science, Technical University of Denmark
30秒速读
IN SHORT: This paper addresses the core challenge of accurately predicting protein fitness with only a handful of experimental observations, where data collection is prohibitively expensive and label availability is severely limited.
核心创新
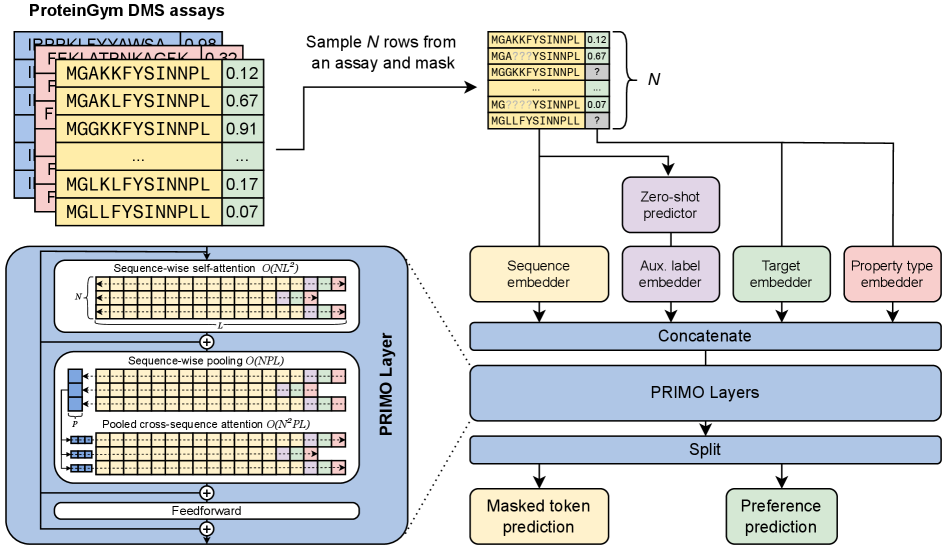
- Methodology Introduces PRIMO, a novel transformer-based framework that uniquely combines in-context learning with test-time training for few-shot protein fitness prediction.
- Methodology Proposes a hybrid masked token reconstruction objective with a preference-based loss function, enabling effective learning from sparse experimental labels across diverse assays.
- Methodology Develops a lightweight pooling attention mechanism that handles both substitution and indel mutations while maintaining computational efficiency, overcoming limitations of previous methods.
主要结论
- PRIMO with test-time training (TTT) achieves state-of-the-art few-shot performance, improving from a zero-shot Spearman correlation of 0.51 to 0.67 with 128 shots, outperforming Gaussian Process (0.56) and Ridge Regression (0.63) baselines.
- The framework demonstrates broad applicability across protein properties including stability (0.77 correlation with TTT), enzymatic activity (0.61), fluorescence (0.30), and binding (0.69), handling both substitution and indel mutations.
- PRIMO's performance highlights the critical importance of proper data splitting to avoid inflated results, as demonstrated by the 0.4 correlation inflation on RL40A_YEAST when using Metalic's overlapping train-test split.
摘要: Accurately predicting protein fitness with minimal experimental data is a persistent challenge in protein engineering. We introduce PRIMO (PRotein In-context Mutation Oracle), a transformer-based framework that leverages in-context learning and test-time training to adapt rapidly to new proteins and assays without large task-specific datasets. By encoding sequence information, auxiliary zero-shot predictions, and sparse experimental labels from many assays as a unified token set in a pre-training masked-language modeling paradigm, PRIMO learns to prioritize promising variants through a preference-based loss function. Across diverse protein families and properties—including both substitution and indel mutations—PRIMO outperforms zero-shot and fully supervised baselines. This work underscores the power of combining large-scale pre-training with efficient test-time adaptation to tackle challenging protein design tasks where data collection is expensive and label availability is limited.