
Paper List
-
Translating Measures onto Mechanisms: The Cognitive Relevance of Higher-Order Information
This review addresses the core challenge of translating abstract higher-order information theory metrics (e.g., synergy, redundancy) into defensible, ...
-
Emergent Bayesian Behaviour and Optimal Cue Combination in LLMs
This paper addresses the critical gap in understanding whether LLMs spontaneously develop human-like Bayesian strategies for processing uncertain info...
-
Vessel Network Topology in Molecular Communication: Insights from Experiments and Theory
This work addresses the critical lack of experimentally validated channel models for molecular communication within complex vessel networks, which is ...
-
Modulation of DNA rheology by a transcription factor that forms aging microgels
This work addresses the fundamental question of how the transcription factor NANOG, essential for embryonic stem cell pluripotency, physically regulat...
-
Imperfect molecular detection renormalizes apparent kinetic rates in stochastic gene regulatory networks
This paper addresses the core challenge of distinguishing genuine stochastic dynamics of gene regulatory networks from artifacts introduced by imperfe...
-
PanFoMa: A Lightweight Foundation Model and Benchmark for Pan-Cancer
This paper addresses the dual challenge of achieving computational efficiency without sacrificing accuracy in whole-transcriptome single-cell represen...
-
Beyond Bayesian Inference: The Correlation Integral Likelihood Framework and Gradient Flow Methods for Deterministic Sampling
This paper addresses the core challenge of calibrating complex biological models (e.g., PDEs, agent-based models) with incomplete, noisy, or heterogen...
-
Contrastive Deep Learning for Variant Detection in Wastewater Genomic Sequencing
This paper addresses the core challenge of detecting viral variants in wastewater sequencing data without reference genomes or labeled annotations, ov...
Training Dynamics of Learning 3D-Rotational Equivariance
Genentech Computational Sciences | New York University
30秒速读
IN SHORT: This work addresses the core dilemma of whether to use computationally expensive equivariant architectures or faster symmetry-agnostic models with data augmentation, by quantifying the speed and extent to which the latter learn 3D rotational symmetry.
核心创新
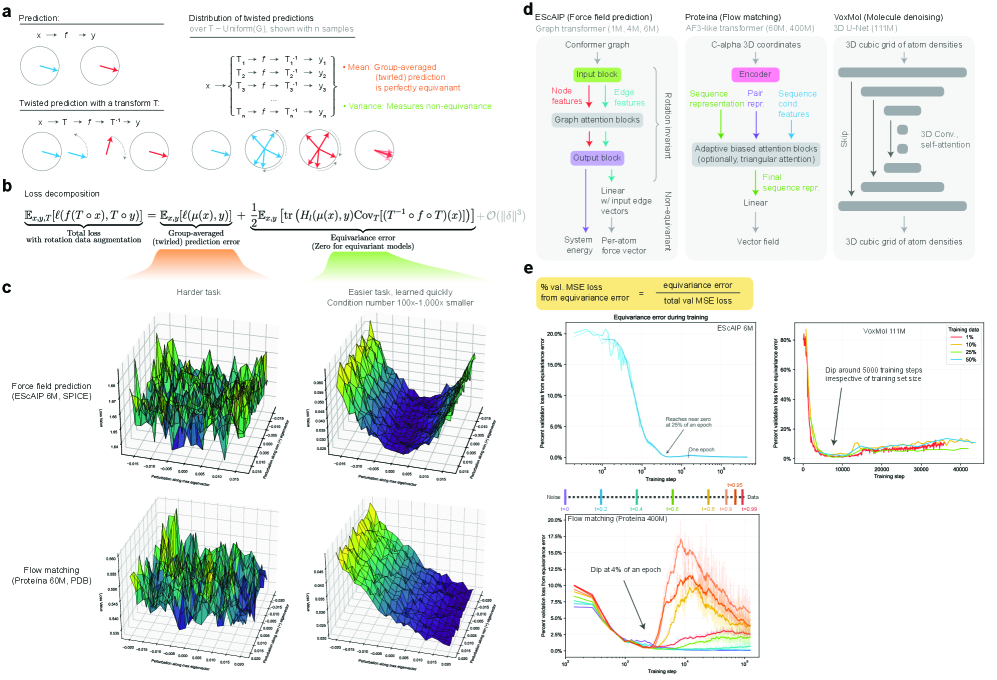
- Methodology Introduces a principled, generalizable framework to decompose total loss into a 'twirled prediction error' (ℒ_mean) and an 'equivariance error' (ℒ_equiv), enabling precise measurement of the percent of loss attributable to imperfect symmetry learning.
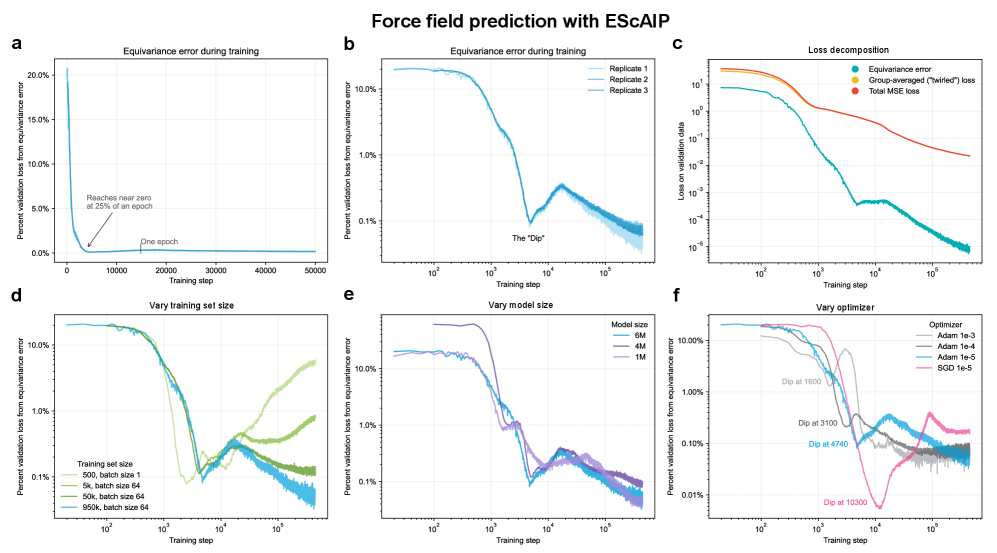
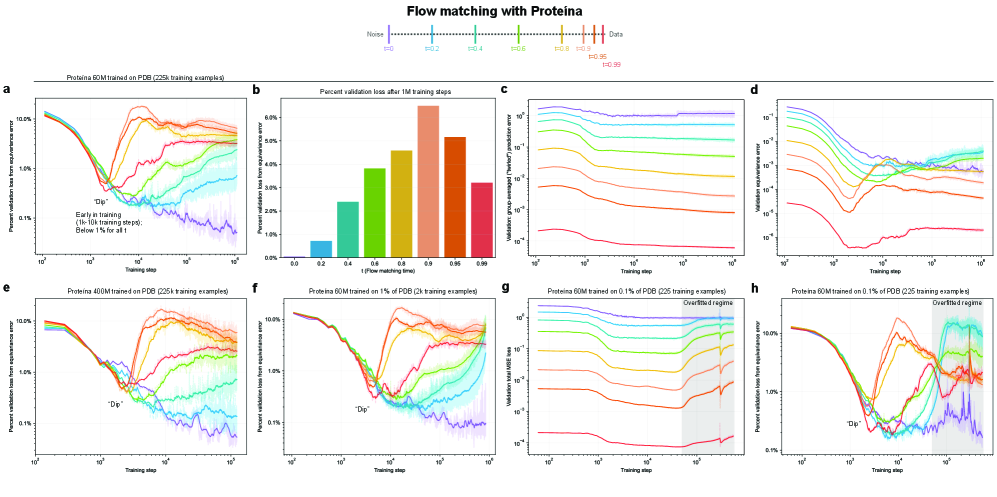
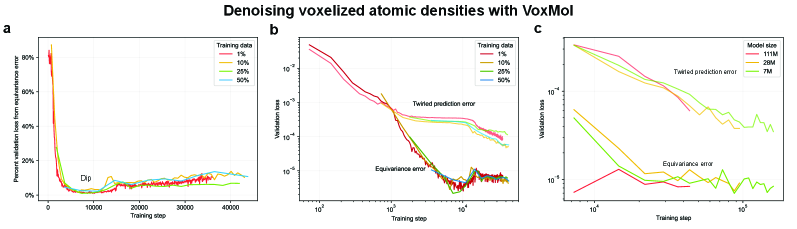
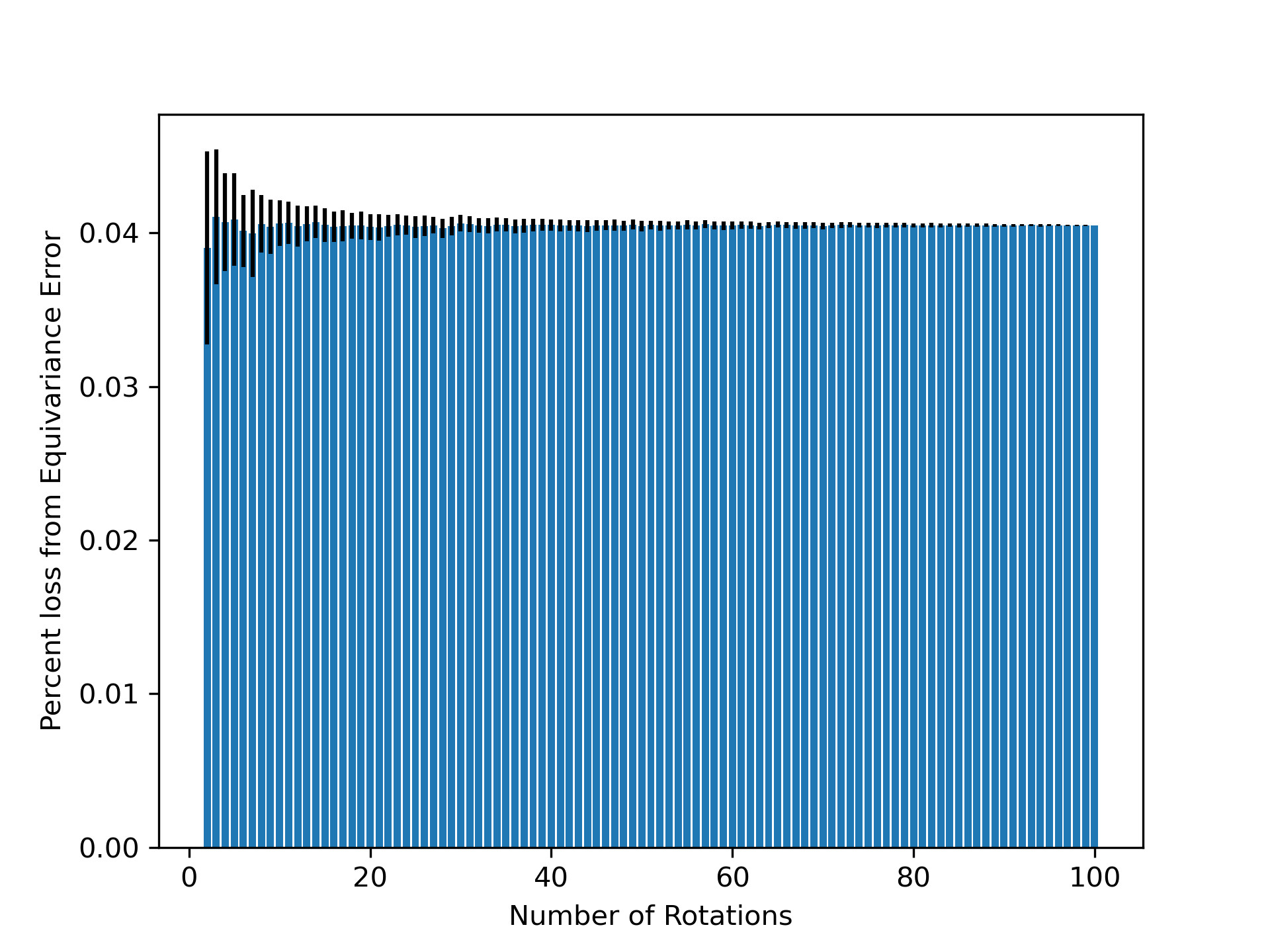
- Methodology Empirically demonstrates that models learning 3D-rotational equivariance via data augmentation achieve very low equivariance error (≤2% of total loss) remarkably quickly, within 1k-10k training steps, across diverse molecular tasks and model scales.
- Theory Provides theoretical and experimental evidence that learning equivariance is an easier task than the main prediction, characterized by a smoother and better-conditioned loss landscape (e.g., 1000x lower condition number for ℒ_equiv vs. ℒ_mean in force field prediction).
主要结论
- Non-equivariant models with data augmentation learn 3D rotational equivariance rapidly and effectively, reducing the equivariance error component to ≤2% of the total validation loss within the first 1k-10k training steps.
- The loss penalty for imperfect equivariance (ℒ_equiv) is small throughout training for 3D rotations, meaning the primary trade-off is the 'efficiency gap' (slower training/inference of equivariant models) rather than a significant accuracy penalty.
- The speed of learning equivariance is robust to model size (1M to 400M parameters), dataset size (500 to 1M samples), and optimizer choice, indicating it is a fundamental property of the learning task landscape.
摘要: While data augmentation is widely used to train symmetry-agnostic models, it remains unclear how quickly and effectively they learn to respect symmetries. We investigate this by deriving a principled measure of equivariance error that, for convex losses, calculates the percent of total loss attributable to imperfections in learned symmetry. We focus our empirical investigation to 3D-rotation equivariance on high-dimensional molecular tasks (flow matching, force field prediction, denoising voxels) and find that models reduce equivariance error quickly to ≤2% held-out loss within 1k-10k training steps, a result robust to model and dataset size. This happens because learning 3D-rotational equivariance is an easier learning task, with a smoother and better-conditioned loss landscape, than the main prediction task. For 3D rotations, the loss penalty for non-equivariant models is small throughout training, so they may achieve lower test loss than equivariant models per GPU-hour unless the equivariant “efficiency gap” is narrowed. We also experimentally and theoretically investigate the relationships between relative equivariance error, learning gradients, and model parameters.