
Paper List
-
The Effective Reproduction Number in the Kermack-McKendrick model with age of infection and reinfection
This paper addresses the challenge of accurately estimating the time-varying effective reproduction number ℛ(t) in epidemics by incorporating two crit...
-
Covering Relations in the Poset of Combinatorial Neural Codes
This work addresses the core challenge of navigating the complex poset structure of neural codes to systematically test the conjecture linking convex ...
-
Collective adsorption of pheromones at the water-air interface
This paper addresses the core challenge of understanding how amphiphilic pheromones, previously assumed to be transported in the gas phase, can be sta...
-
pHapCompass: Probabilistic Assembly and Uncertainty Quantification of Polyploid Haplotype Phase
This paper addresses the core challenge of accurately assembling polyploid haplotypes from sequencing data, where read assignment ambiguity and an exp...
-
Setting up for failure: automatic discovery of the neural mechanisms of cognitive errors
This paper addresses the core challenge of automating the discovery of biologically plausible recurrent neural network (RNN) dynamics that can replica...
-
Influence of Object Affordance on Action Language Understanding: Evidence from Dynamic Causal Modeling Analysis
This study addresses the core challenge of moving beyond correlational evidence to establish the *causal direction* and *temporal dynamics* of how obj...
-
Revealing stimulus-dependent dynamics through statistical complexity
This paper addresses the core challenge of detecting stimulus-specific patterns in neural population dynamics that remain hidden to traditional variab...
-
Exactly Solvable Population Model with Square-Root Growth Noise and Cell-Size Regulation
This paper addresses the fundamental gap in understanding how microscopic growth fluctuations, specifically those with size-dependent (square-root) no...
Training Dynamics of Learning 3D-Rotational Equivariance
Genentech Computational Sciences | New York University
30秒速读
IN SHORT: This work addresses the core dilemma of whether to use computationally expensive equivariant architectures or faster symmetry-agnostic models with data augmentation, by quantifying the speed and extent to which the latter learn 3D rotational symmetry.
核心创新
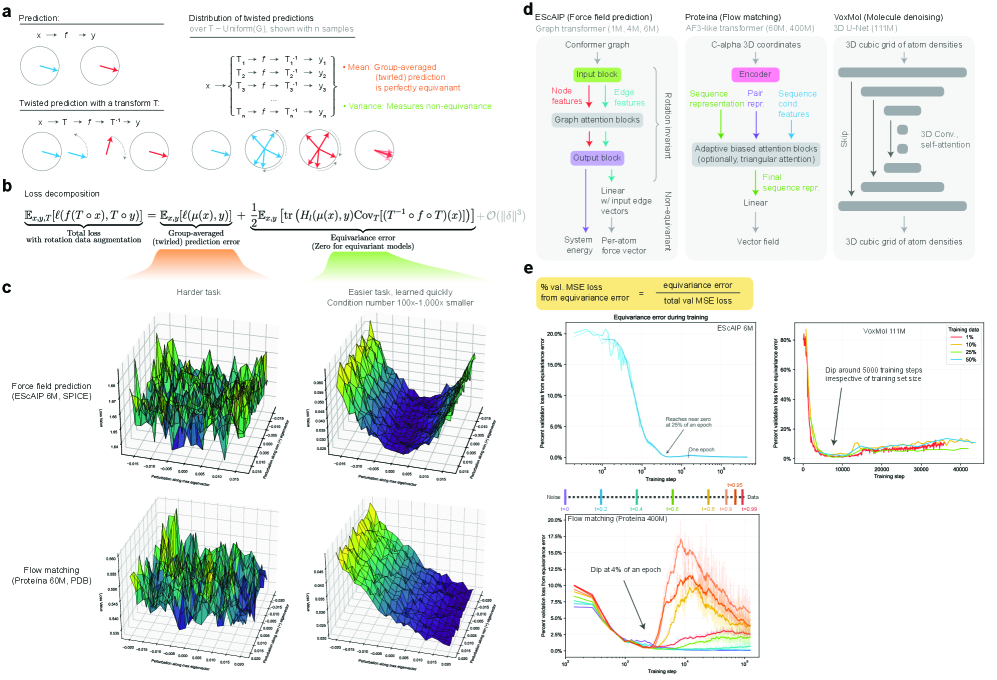
- Methodology Introduces a principled, generalizable framework to decompose total loss into a 'twirled prediction error' (ℒ_mean) and an 'equivariance error' (ℒ_equiv), enabling precise measurement of the percent of loss attributable to imperfect symmetry learning.
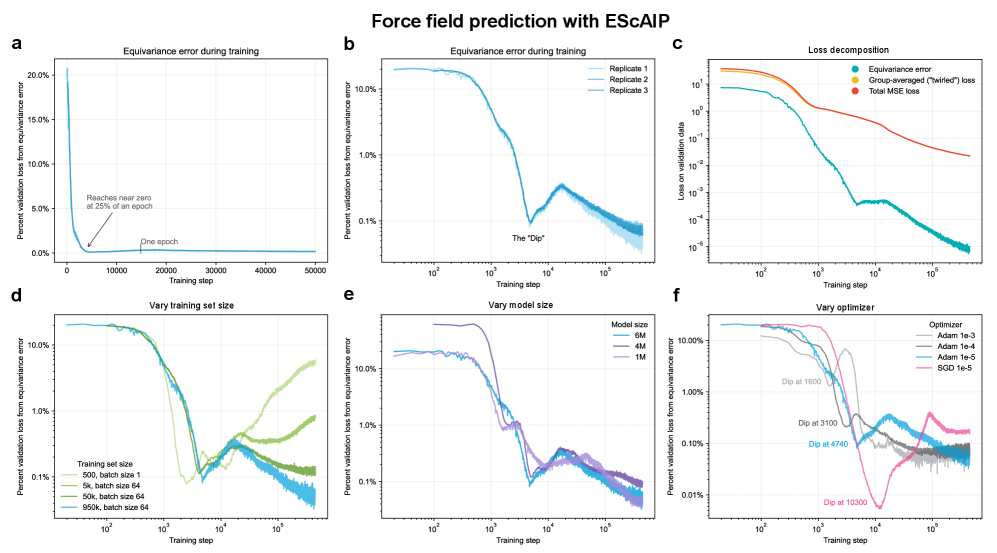
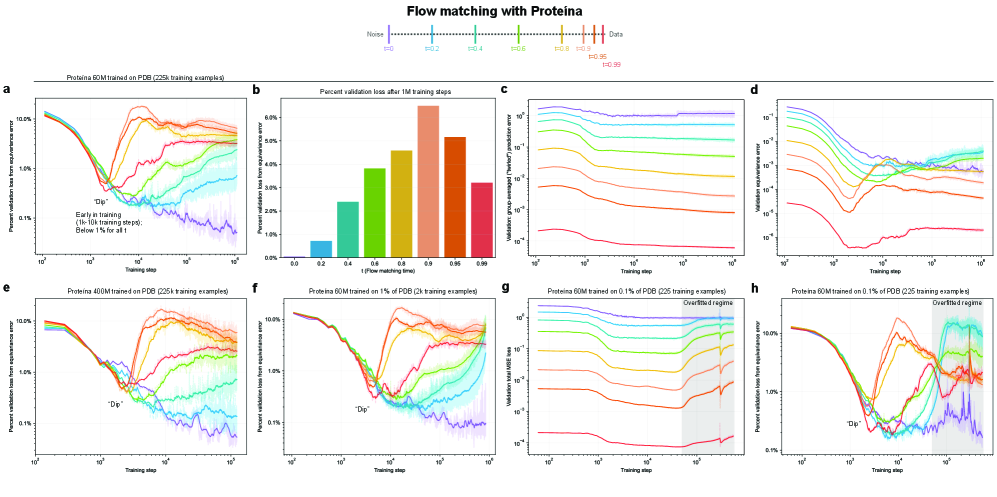
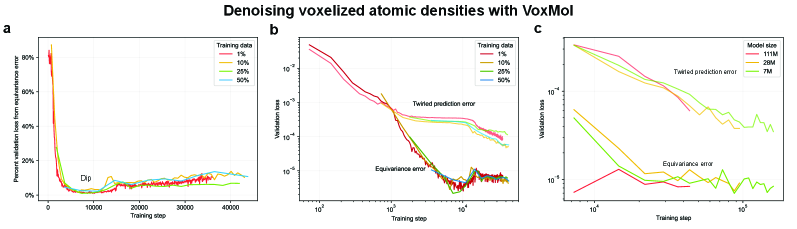
- Methodology Empirically demonstrates that models learning 3D-rotational equivariance via data augmentation achieve very low equivariance error (≤2% of total loss) remarkably quickly, within 1k-10k training steps, across diverse molecular tasks and model scales.
- Theory Provides theoretical and experimental evidence that learning equivariance is an easier task than the main prediction, characterized by a smoother and better-conditioned loss landscape (e.g., 1000x lower condition number for ℒ_equiv vs. ℒ_mean in force field prediction).
主要结论
- Non-equivariant models with data augmentation learn 3D rotational equivariance rapidly and effectively, reducing the equivariance error component to ≤2% of the total validation loss within the first 1k-10k training steps.
- The loss penalty for imperfect equivariance (ℒ_equiv) is small throughout training for 3D rotations, meaning the primary trade-off is the 'efficiency gap' (slower training/inference of equivariant models) rather than a significant accuracy penalty.
- The speed of learning equivariance is robust to model size (1M to 400M parameters), dataset size (500 to 1M samples), and optimizer choice, indicating it is a fundamental property of the learning task landscape.
摘要: While data augmentation is widely used to train symmetry-agnostic models, it remains unclear how quickly and effectively they learn to respect symmetries. We investigate this by deriving a principled measure of equivariance error that, for convex losses, calculates the percent of total loss attributable to imperfections in learned symmetry. We focus our empirical investigation to 3D-rotation equivariance on high-dimensional molecular tasks (flow matching, force field prediction, denoising voxels) and find that models reduce equivariance error quickly to ≤2% held-out loss within 1k-10k training steps, a result robust to model and dataset size. This happens because learning 3D-rotational equivariance is an easier learning task, with a smoother and better-conditioned loss landscape, than the main prediction task. For 3D rotations, the loss penalty for non-equivariant models is small throughout training, so they may achieve lower test loss than equivariant models per GPU-hour unless the equivariant “efficiency gap” is narrowed. We also experimentally and theoretically investigate the relationships between relative equivariance error, learning gradients, and model parameters.