
Paper List
-
STAR-GO: Improving Protein Function Prediction by Learning to Hierarchically Integrate Ontology-Informed Semantic Embeddings
This paper addresses the core challenge of generalizing protein function prediction to unseen or newly introduced Gene Ontology (GO) terms by overcomi...
-
Incorporating indel channels into average-case analysis of seed-chain-extend
This paper addresses the core pain point of bridging the theoretical gap for the widely used seed-chain-extend heuristic by providing the first rigoro...
-
Competition, stability, and functionality in excitatory-inhibitory neural circuits
This paper addresses the core challenge of extending interpretable energy-based frameworks to biologically realistic asymmetric neural networks, where...
-
Enhancing Clinical Note Generation with ICD-10, Clinical Ontology Knowledge Graphs, and Chain-of-Thought Prompting Using GPT-4
This paper addresses the core challenge of generating accurate and clinically relevant patient notes from sparse inputs (ICD codes and basic demograph...
-
Learning From Limited Data and Feedback for Cell Culture Process Monitoring: A Comparative Study
This paper addresses the core challenge of developing accurate real-time bioprocess monitoring soft sensors under severe data constraints: limited his...
-
Cell-cell communication inference and analysis: biological mechanisms, computational approaches, and future opportunities
This review addresses the critical need for a systematic framework to navigate the rapidly expanding landscape of computational methods for inferring ...
-
Generating a Contact Matrix for Aged Care Settings in Australia: an agent-based model study
This study addresses the critical gap in understanding heterogeneous contact patterns within aged care facilities, where existing population-level con...
-
Emergent Spatiotemporal Dynamics in Large-Scale Brain Networks with Next Generation Neural Mass Models
This work addresses the core challenge of understanding how complex, brain-wide spatiotemporal patterns emerge from the interaction of biophysically d...
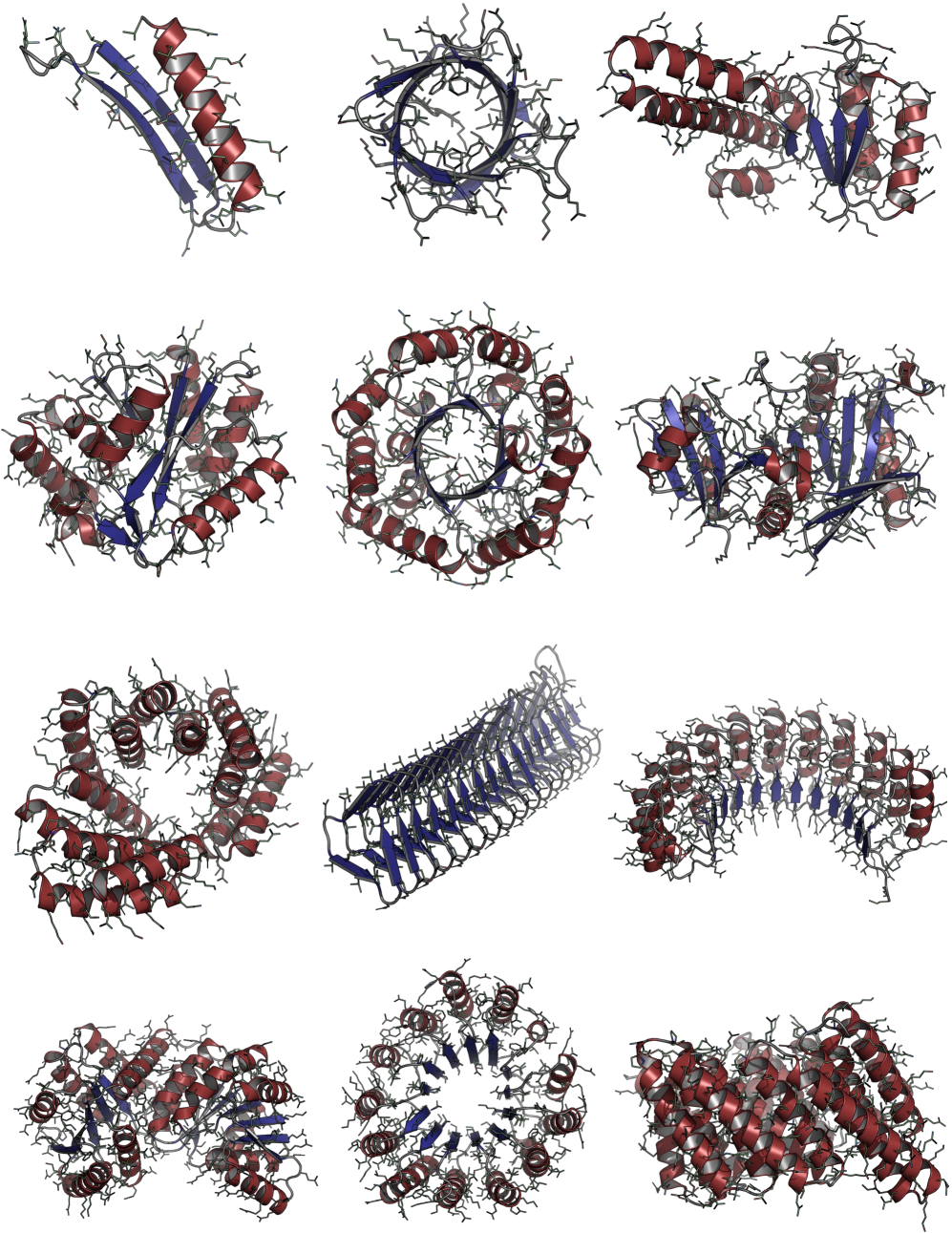
Consistent Synthetic Sequences Unlock Structural Diversity in Fully Atomistic De Novo Protein Design
NVIDIA | Mila - Quebec AI Institute | Université de Montréal | HEC Montréal | CIFAR AI Chair
30秒速读
IN SHORT: This paper addresses the core pain point of low sequence-structure alignment in existing synthetic datasets (e.g., AFDB), which severely limits the performance of fully atomistic protein generative models.
核心创新
- Methodology Introduces a novel high-quality synthetic dataset (D_SYN-ours, ~0.46M samples) by leveraging ProteinMPNN for sequence generation and ESMFold for refolding, ensuring aligned and recoverable sequence-structure pairs.
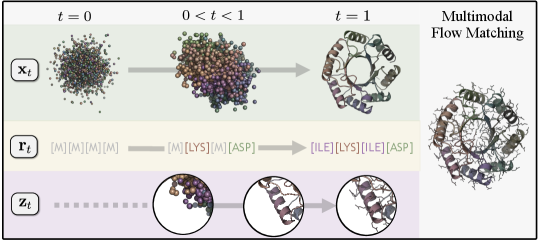
- Methodology Proposes Proteína-Atomística, a unified multi-modal flow-based framework that jointly models the distribution of Cα backbone atoms, discrete amino acid sequences, and non-Cα side-chain atoms in explicit observable space without latent variables.
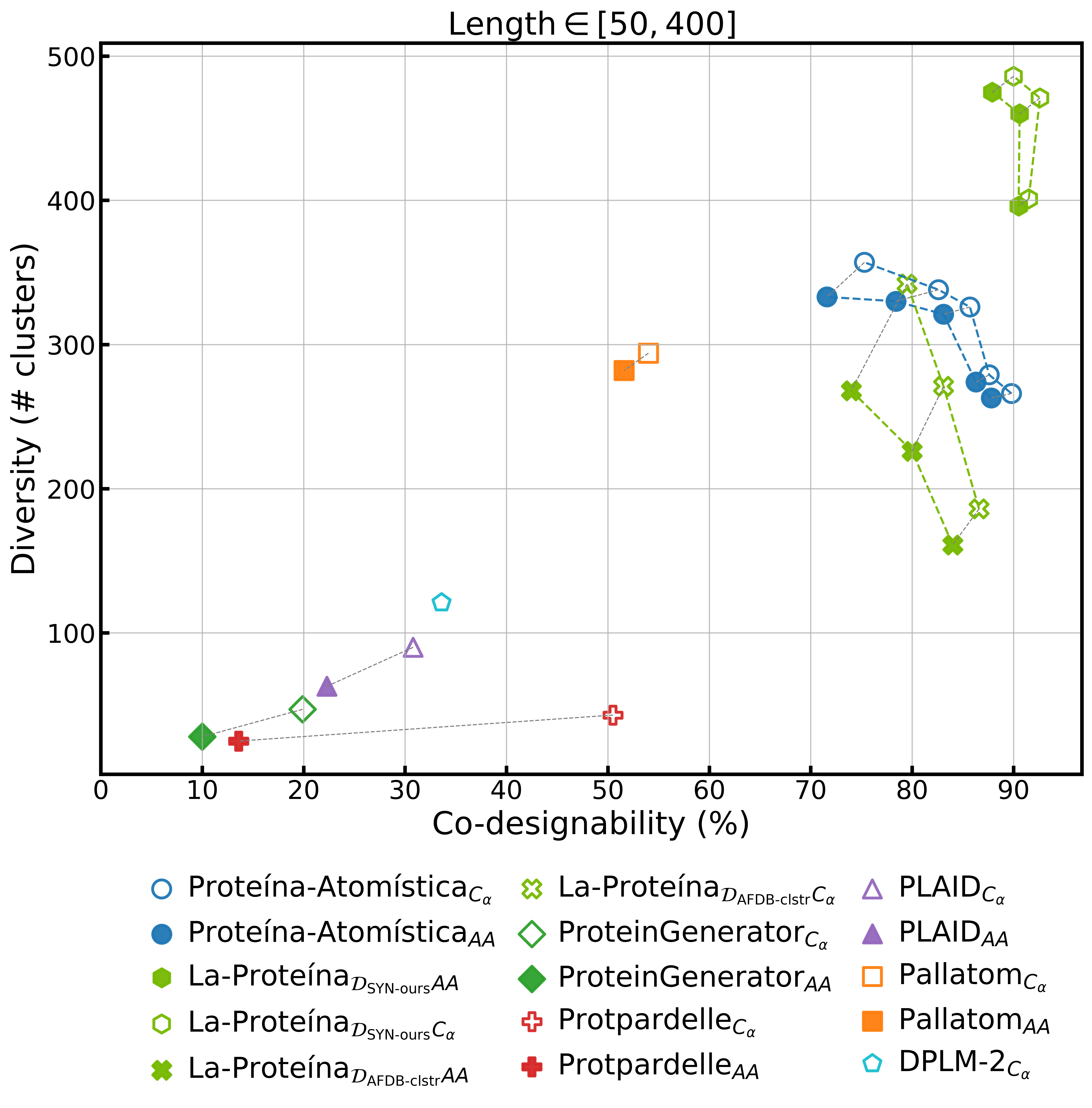
- Biology Demonstrates that consistent synthetic sequences are critical for unlocking structural diversity, with retrained La-Proteína achieving +54% structural diversity and +27% co-designability, and Proteína-Atomística achieving +73% structural diversity and +5% co-designability.
主要结论
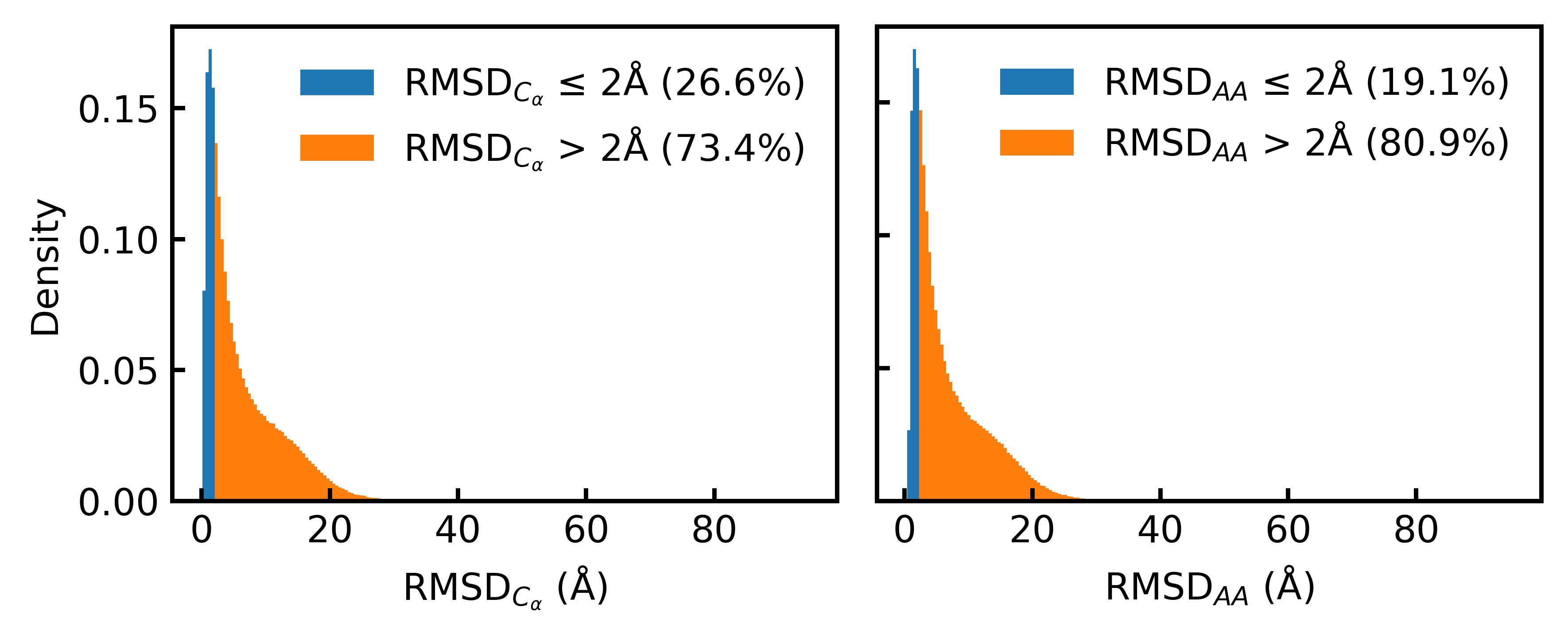
- Only 19.1% of the Foldseek-clustered AFDB dataset (D_AFDB-clstr) meets the standard 2Å all-atom RMSD co-designability threshold when refolded with ESMFold, revealing severe sequence-structure misalignment.
- Training on the new aligned dataset D_SYN-ours boosts La-Proteína's performance by +54% in structural diversity and +27% in co-designability, setting a new state-of-the-art.
- The proposed Proteína-Atomística framework, when trained on D_SYN-ours, shows a dramatic +73% improvement in structural diversity and a +5% improvement in co-designability, validating the dataset's broad utility.
摘要: High-quality training datasets are crucial for the development of effective protein design models, but existing synthetic datasets often include unfavorable sequence-structure pairs, impairing generative model performance. We leverage ProteinMPNN, whose sequences are experimentally favorable as well as amenable to folding, together with structure prediction models to align high-quality synthetic structures with recoverable synthetic sequences. In that way, we create a new dataset designed specifically for training expressive, fully atomistic protein generators. By retraining La-Proteína, which models discrete residue type and side chain structure in a continuous latent space, on this dataset, we achieve new state-of-the-art results, with improvements of +54% in structural diversity and +27% in co-designability. To validate the broad utility of our approach, we further introduce Proteína-Atomística, a unified flow-based framework that jointly learns the distribution of protein backbone structure, discrete sequences, and atomistic side chains without latent variables. We again find that training on our new sequence-structure data dramatically boosts benchmark performance, improving Proteína-Atomística’s structural diversity by +73% and co-designability by +5%. Our work highlights the critical importance of aligned sequence-structure data for training high-performance de novo protein design models. All data will be publicly released.