
Paper List
-
Discovery of a Hematopoietic Manifold in scGPT Yields a Method for Extracting Performant Algorithms from Biological Foundation Model Internals
This work addresses the core challenge of extracting reusable, interpretable, and high-performance biological algorithms from the opaque internal repr...
-
MS2MetGAN: Latent-space adversarial training for metabolite–spectrum matching in MS/MS database search
This paper addresses the critical bottleneck in metabolite identification: the generation of high-quality negative training samples that are structura...
-
Toward Robust, Reproducible, and Widely Accessible Intracranial Language Brain-Computer Interfaces: A Comprehensive Review of Neural Mechanisms, Hardware, Algorithms, Evaluation, Clinical Pathways and Future Directions
This review addresses the core challenge of fragmented and heterogeneous evidence that hinders the clinical translation of intracranial language BCIs,...
-
Less Is More in Chemotherapy of Breast Cancer
通过纳入细胞周期时滞和竞争项,解决了现有肿瘤-免疫模型的过度简化问题,以定量比较化疗方案。
-
Fold-CP: A Context Parallelism Framework for Biomolecular Modeling
This paper addresses the critical bottleneck of GPU memory limitations that restrict AlphaFold 3-like models to processing only a few thousand residue...
-
Open Biomedical Knowledge Graphs at Scale: Construction, Federation, and AI Agent Access with Samyama Graph Database
This paper addresses the core pain point of fragmented biomedical data by constructing and federating large-scale, open knowledge graphs to enable sea...
-
Predictive Analytics for Foot Ulcers Using Time-Series Temperature and Pressure Data
This paper addresses the critical need for continuous, real-time monitoring of diabetic foot health by developing an unsupervised anomaly detection fr...
-
Hypothesis-Based Particle Detection for Accurate Nanoparticle Counting and Digital Diagnostics
This paper addresses the core challenge of achieving accurate, interpretable, and training-free nanoparticle counting in digital diagnostic assays, wh...
DeepFRI Demystified: Interpretability vs. Accuracy in AI Protein Function Prediction
Yale University | Microsoft
30秒速读
IN SHORT: This study addresses the critical gap between high predictive accuracy and biological interpretability in DeepFRI, revealing that the model often prioritizes structural motifs over functional residues, complicating reliable identification of drug targets.
核心创新
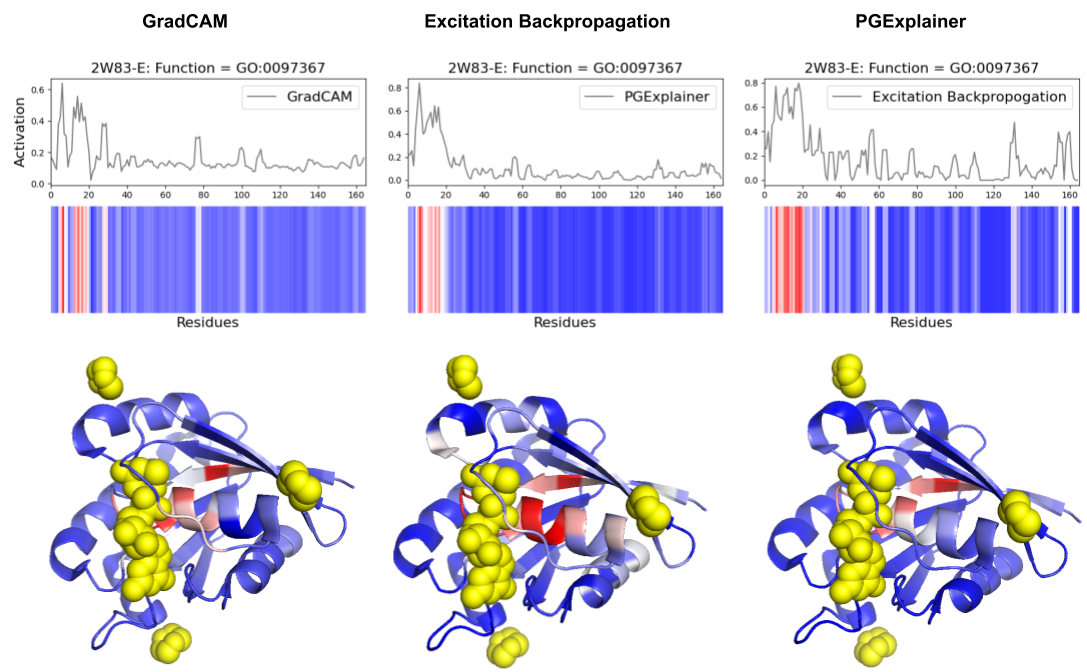
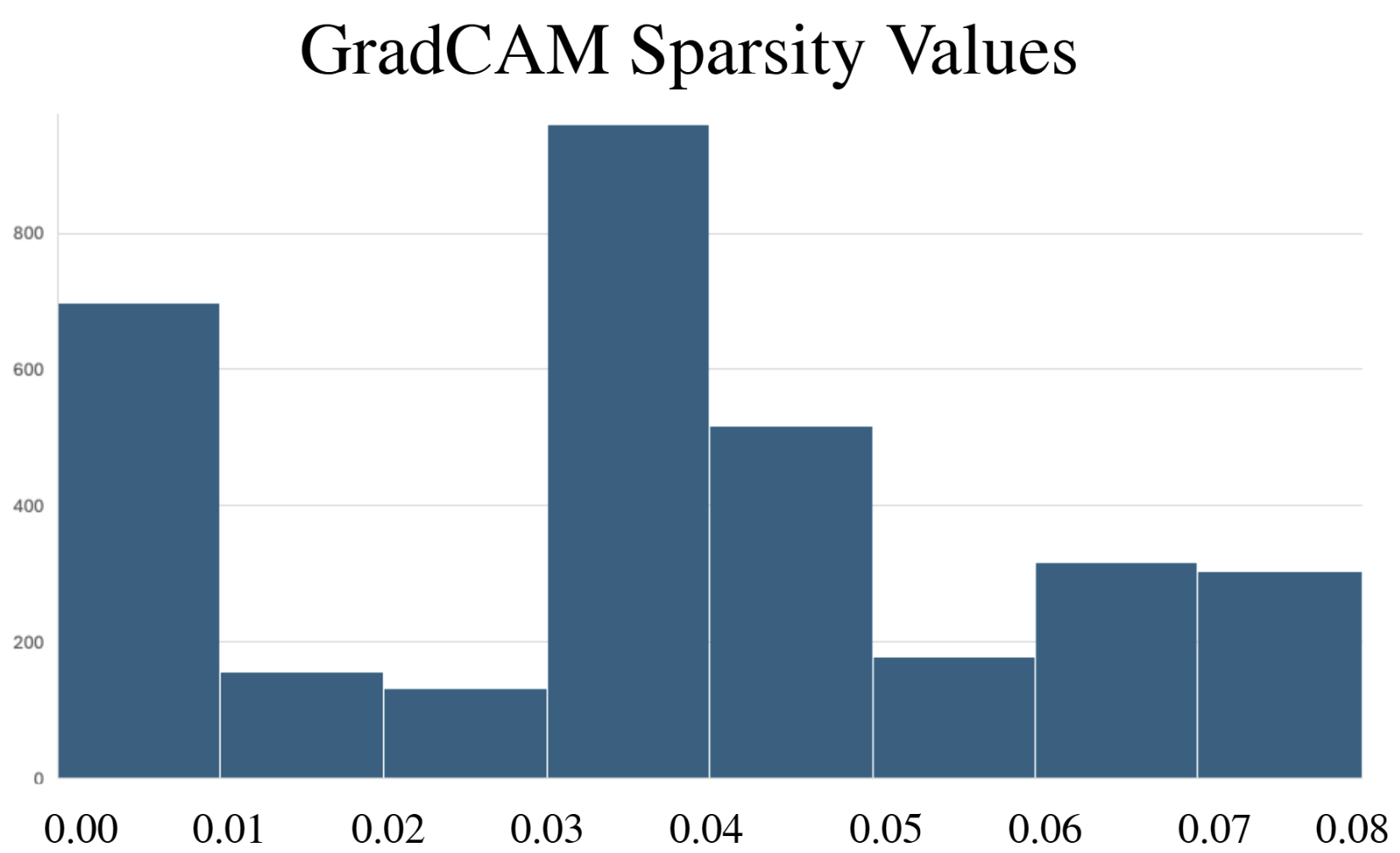
- Methodology Comprehensive benchmarking of three post-hoc explainability methods (GradCAM, Excitation Backpropagation, PGExplainer) on DeepFRI with quantitative sparsity analysis.
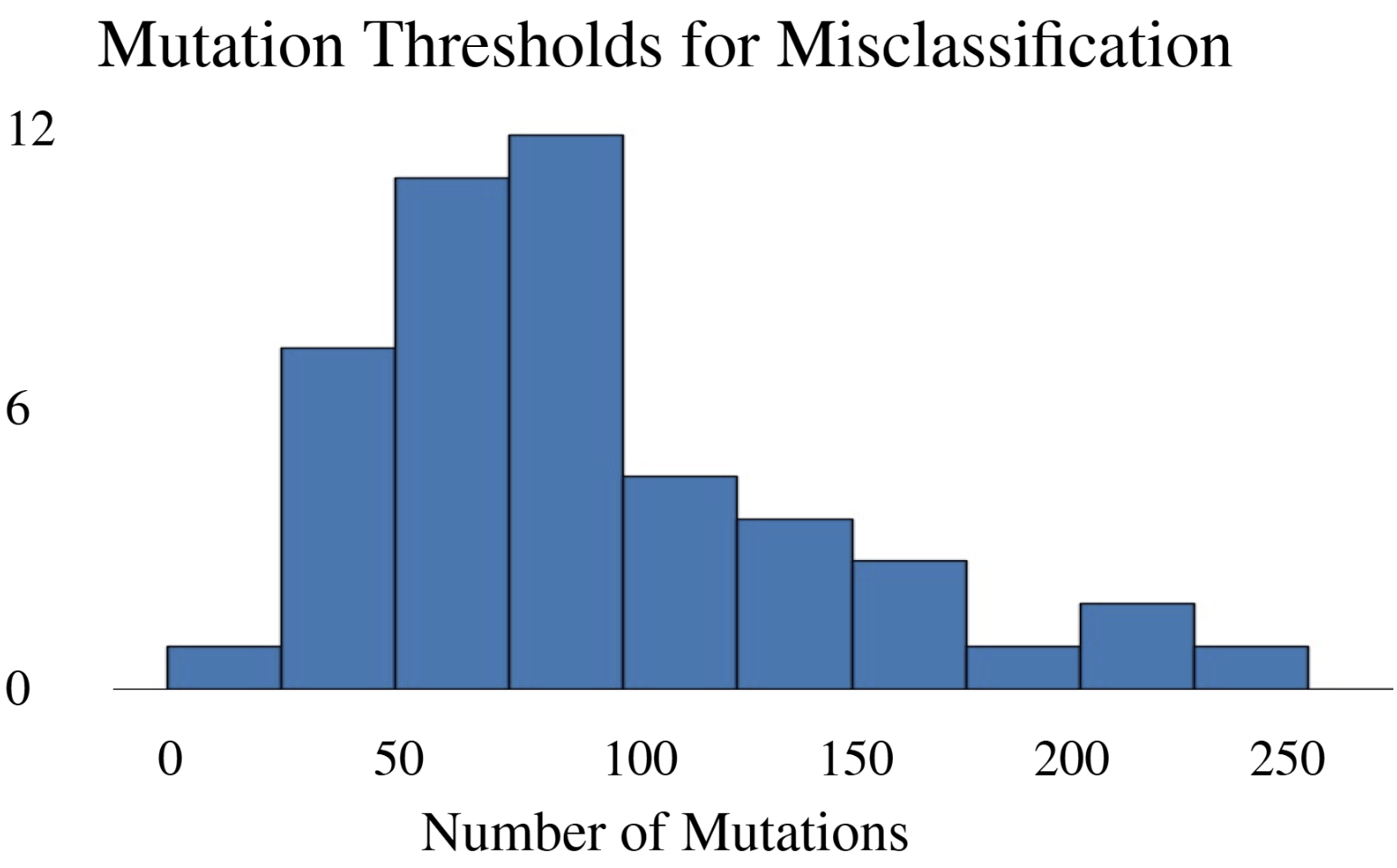
- Methodology Development of a modified DeepFool adversarial testing framework for protein sequences, measuring mutation thresholds required for misclassification.
- Biology Revealed that DeepFRI prioritizes amino acids controlling protein structure over function in >50% of tested proteins, highlighting a fundamental accuracy-interpretability trade-off.
主要结论
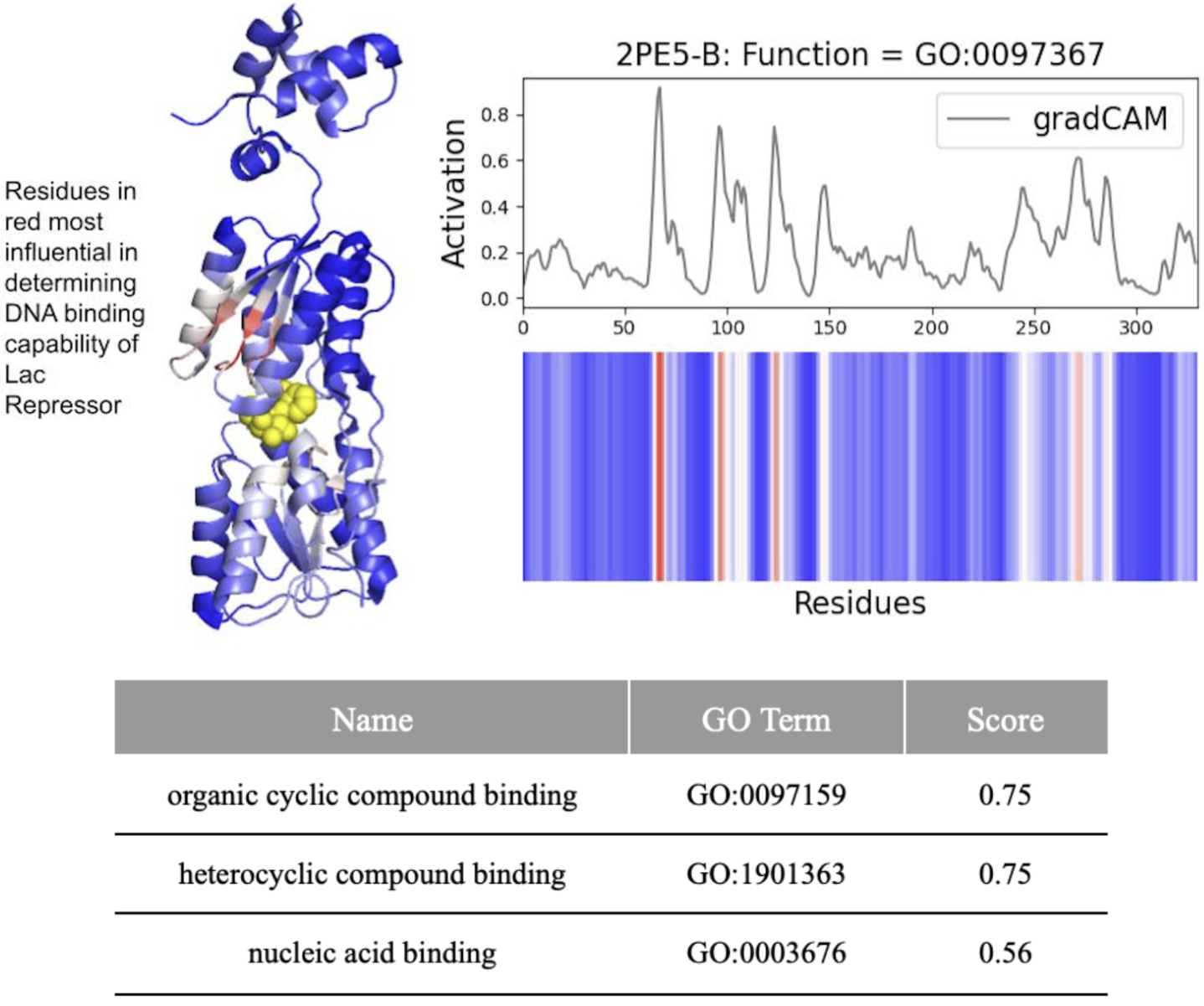
- DeepFRI required 206 mutations (62.4% of 330 residues) in the lac repressor for misclassification, demonstrating extreme robustness but potentially missing subtle functional alterations.
- Explainability methods showed significant granularity differences: PGExplainer was 3× sparser than GradCAM and 17× sparser than Excitation Backpropagation across 124 binding proteins.
- All three methods converged on biochemically critical P-loop residues (0-20) in ARF6 GTPase, validating DeepFRI's focus on conserved functional motifs in straightforward domains.
摘要: Machine learning technologies for protein function prediction are black box models. Despite their potential to identify key drug targets with high accuracy and accelerate therapy development, the adoption of these methods depends on verifying their findings. This study evaluates DeepFRI, a leading Graph Convolutional Network (GCN)-based tool, using advanced explainability techniques—GradCAM, Excitation Backpropagation, and PGExplainer—and adversarial robustness tests. Our findings reveal that the model’s predictions often prioritize conserved motifs over truly deterministic residues, complicating the identification of functional sites. Quantitative analyses show that explainability methods differ significantly in granularity, with GradCAM providing broad relevance and PGExplainer pinpointing specific active sites. These results highlight trade-offs between accuracy and interpretability, suggesting areas for improvement in DeepFRI’s architecture to enhance its trustworthiness in drug discovery and regulatory settings.